热门关键词: 石墨制品 | 纯矽制品 | 特殊金属 | 金属制品 | 陶瓷制品 | 石英制品 | 二手设备
专业的半导体机台服务应用公司
范围:Lam 9400、9600、4520、2300——
AMAT P500, DPS, centura, endura——
全国服务热线 0519-68910861


 启闳半导体科技(江苏)有限公司
启闳半导体科技(江苏)有限公司Hotchips是全球最具有影响力的芯片会议之一,其主要针对芯片工业界展示最新的研发成果,以及披露最新产品中的重要技术。上周,第34届Hotchips刚刚落下帷幕,本文将本届Hotchips中表现出来的业界动向做一个分析。
随着人工智能等高性能计算应用的持续火热,这些方向也成为了半导体芯片行业发展最重要的驱动力之一。本届Hotchips的亮点无疑是支持这些应用方向的芯片,尤其是应用于边缘和数据中心的这类高性能计算赋能芯片。在本届Hotchips共两天七个主题议程中,约有一半的相关论文和这些高性能计算有关,涵盖了GPGPU、机器学习加速、ADAS和高性能网络开关等领域,而这些相关论文都来自Nvidia、AMD、Intel、Tesla等业界最顶尖的芯片公司,论文内容则是关于公司最新芯片的关键技术。这些赋能云端高性能计算的芯片有一个共同的特点,就是规模越做越大,而本届Hotchips中我们也可以看到芯片设计行业正在使用全新的工具来确保芯片规模的继续上升,而这些工具就是芯片粒/高级封装以及芯片-软件协同设计。如果说基于IP复用的SoC理念创造了上一代大规模集成芯片的蓬勃发展的话,那么芯片粒和软件协同设计将会成为芯片突破集成度瓶颈并进一步提升芯片功能和晶体管规模的下一代支柱。
芯片粒是未来高性能芯片的支柱
随着高性能计算对于芯片性能(包括算力、互联和内存接口)的需求持续上升,整个芯片系统的晶体管规模和设计复杂度也在相应提升。这样的性能需求上升是指数级的:以Nvidia的GPU算力为例,一般的规律是每一代(两年)GPU的性能相对于上一代提升两到三倍。为了应对指数级上升的性能需求,芯片系统必须要从两个方面实现不断提升,其一是单芯片的性能,其二是可扩展性。单芯片的性能提升约等于在芯片中加入更多的晶体管,其主要挑战在于如何提升良率和降低成本,因为芯片的良率随着晶体管数量提升(即芯片面积上升)而快速下降,单纯堆积晶体管的做法会导致良率低到无法接受。除此之外,还需要确保芯片系统设计是可扩展的,即可以把多个单元芯片协同工作以进一步提升性能。可协同性的主要挑战在于IO带宽,如果IO成为瓶颈的话,那么多个单元芯片协同工作的性能并不会比单元芯片强很多。
为了解决良率和可扩展性的问题,芯片粒加高级封装技术就成为了目前芯片厂商普遍的答案。在这样的方案中,首先不再追求每个单元芯片的集成度,而是把单元芯片做成面积较小的芯片粒,这样芯片粒的良率会远远高于大芯片。同时,将多个芯片粒用高级封装的技术集成到一起来实现大规模芯片系统,由于高级封装技术同时提供了大带宽的高性能互联,这样就就解决了可扩展性问题。
在本届Hotchips上,我们可以看到芯片粒加高级封装已经成为了高性能计算的主流解决方案。Intel的Ponte Vecchio是本届Hotchips的一大亮点:Ponte Vecchio是Intel的下一代GPU架构,其设计中使用了大规模芯片粒和高级封装技术,而在本次Hotchips上Intel公布了Ponte Vecchio的最新架构细节和相关数据。在Ponte Vecchio中,会有多个Xe 核心使用高级封装(EMIB)的方式组成compute tile,而L2 Cache则有相应的一个芯片粒(称为Cambo cache tile),并且和compute tile集成到一起。而除此之外,还有HMB和用于芯片间互联的Xe Link芯片粒,这些芯片粒组成了整个Ponte Vecchio系统。由于使用芯片粒的方式,我们看到Intel可以在良率可控的情况下加入大量的Xe核和海量缓存(cache):整个Ponte Vecchio包括了128个Xe核,64MB的register file,64MB的L1 cache和408MB的L2 cache。整个Ponte Vecchio系统可以实现839 TFLOPS的峰值浮点数算力以及1678 TOPS的峰值整数算力,在实现如此高算力的超大规模芯片系统中,芯片粒和高级封装技术可谓是居功至伟。

在Intel的Ponte Vecchio之外,Tesla也公布了其用于人工智能模型训练的Dojo芯片。在Dojo芯片系统中,其基本的计算chiplet是D1,每个D1包括了362TFlops算力和440MB SRAM,同时每个Dojo则包含了25个这样的D1芯片粒以及40个专用的IO芯片粒,使用TSMC的system-on-wafer技术集成到一起,从而实现超大算力支持。

在Intel和Tesla之外,AMD在本届Hotchips上也带来了其MI200系列高算力GPU加速芯片,这也是全球第一个使用芯片粒技术的GPU。AMD将两块芯片粒封装在一起,同时使用400GB/s的高带宽封装内互联确保不同的芯片粒之间能高效互联,每个芯片系统包含了580亿个晶体管,使用TSMC 6nm制造。MI200是AMD在GPGPU领域的重要布局,我们从中看到芯片粒也起了至关重要的作用,而在其下一代MI300 GPGPU目前公布的信息来看,AMD将会进一步加强芯片粒和高级封装技术的作用,从而实现更大规模和更高性能的芯片系统。
芯片和软件协同设计将成为主流
在芯片粒之外,另一个值得我们关注的动向是芯片和软件协同设计。如前所述,芯片系统的规模正在越来越大,模块越来越多,功能越来越复杂,如果没有一个好的软件系统和生态的话,具体的应用很难充分利用芯片提供的性能,从而看到的就是实际应用中的实际性能和芯片的峰值性能相差甚远。更进一步,随着人工智能这类算法驱动类应用的火热,如何结合算法来做芯片的优化和设计也是进一步提升芯片性能的重要方法之一。而我们在本届Hotchips上也确实看到了软件和算法相关优化成为了厂商在演讲内容中的重点。
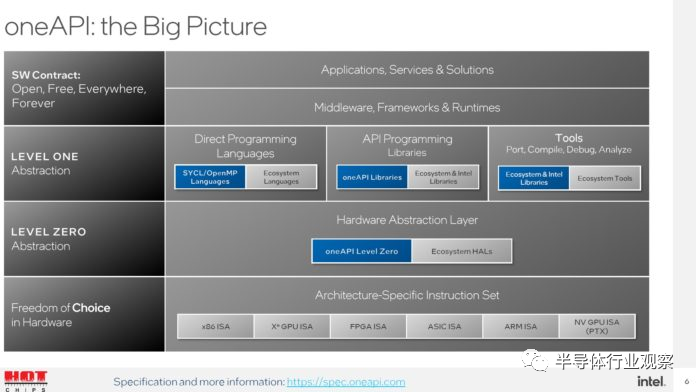
Intel在本届Hotchips上的Ponte Vecchio演讲中,一个重点就是其OneAPI软件接口以及DPC++工具。OneAPI使用一个API来支持不同的底层硬件,从而理想的情况下无需修改应用的软件代码,只需要在OneAPI中直接指定相应的后端执行硬件就可以。OneAPI计划会支持至少Intel的CPU和GPU,可望大大减少应用所需要的软件工作。另一方面,DPC++则是Intel对于目前CUDA生态的回应,使用DPC++可以将已有的为CUDA编写的程序直接移植到Intel的GPU上,这样就大大增加了Intel生态的吸引力。

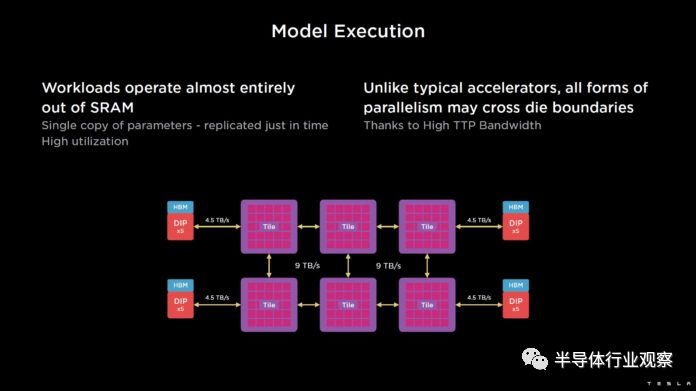
软件在Tesla的Dojo芯片中也起到了至关重要的作用。如前所述,Dojo的设计牵涉到大量的compute tile,如何在不同的compute tile之间分配任务就成了决定整体系统性能的关键;除此之外,如何在不同的Dojo芯片之间分配任务也决定了整体系统的可扩展性。在Tesla的解决方案中,编译器软件将会确保将模型并行化处理并且加载到不同的compute tile中,同时尽量保证模型需要的数据都能装入片上SRAM中以保证性能降低对外部DRAM的依赖。除了编译器之外,Tesla在软件-芯片协同设计中另一个值得一提的是使用了独特的数值表示方式,在常见的FP16和BFP16之外还支持自研的CFP8和CFP16格式的数值表示方式并且在芯片中做了相应支持。根据Tesla公布的材料使用CFP8和CFP16可以获得更好的模型训练效果,而这也是软件-芯片协同设计的很好例子。
在Intel和Tesla之外,在本届Hotchips上和AI相关的演讲几乎都会涉及软件-芯片协同设计,其中包括了业界巨头如Nvidia(Hopper GPU中使用了FP8和Transformer Engine),以及新锐初创公司如Untether AI(公布了UAI FP8数制和imAIgine SDK)和壁仞(TF32+数制和BIRENSUPA软件平台)。我们认为,软件-芯片协同设计正在成为芯片行业进一步推动芯片规模更上一个台阶背后的重要支柱之一,只有在有了强而有力的软件支持,以及对于算法的深入理解后,芯片规模进一步提升才会有相应的回报。










扫一扫